Organizacja pracy w projekcie IT
Jak pewnie mieliście okazję już przeczytać, to całkiem niedawno wystartowałem z całkowicie nowym projektem programistycznym, o którym nieco więcej pisałem w artykule „Development blog #0: Way of Working„. Jako że od tego czasu minęło już parę dni, tak więc obiecywałem, przyszła pora na opisanie kilku technicznych aspektów tego przedsięwzięcia. Zaczniemy oczywiście od tego w jaki sposób zorganizowałem całą pracę związaną zarówno z kodem jak i organizacją zadań czyli tasków. Jesteście ciekawi? Zapraszam wiec do lektury…

Fot: pxhere.com, CC0 Public Domain.
Narzędzia
Do prowadzenia całego projektu wybrałem serwis Gitlab.com. Część z Was pewnie go doskonale zna, ale dla tych, którzy nie mieli z nim styczności napiszę parę zdań.
Gitlab jest webowym managerem gita umożliwiającym hostowanie repozytoriów oraz zarządzanie nimi. Dodatkowo serwis ten jest wyposażony jest w szereg narzędzie umożliwiających zarządzenie projektem. Co ciekawe, umożliwia on nam również skonfigurowanie własnych testów automatycznych (CI – continuous integration), co nie ukrywam jest bardzo fajnym rozwiązaniem. Dodatkowo stworzenie własnego prywatnego projektu jest całkowicie darmowe (w przeciwieństwie do GitHub’a). Oczywiście portal ten jak każdy inny ma również swoje wady, jedną z nich jest na przykład brak możliwości stworzenia kilku repozytoriów w ramach jednego projektu, a co za tym idzie jednego boarda.
Repozytorium
Gałęzie
Podstawowym elementem repozytorium są dwa branche (pl. gałęzie), master oraz develop (równoległy do mastera).
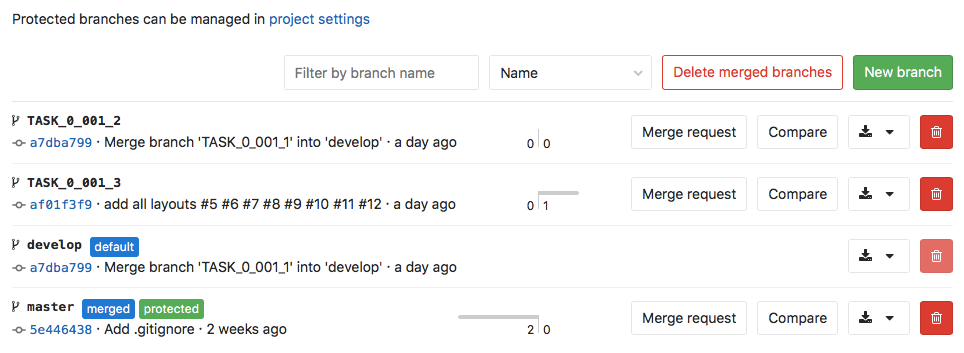
Lista aktualnych branchy w projekcie.
Master jak sama nazwa wskazuje jest gałęzią chronioną do której merge requesty mogę akceptować tylko ja (jako główny developer i zarazem product owner całego projektu). Chodzi o to, że na tej gałęzi ma znajdować się tylko kod w 100% przetestowany i co najważniejsze działający bez żadnego zarzutu! Jest to innymi słowy wersja produkcyjna aplikacji, która zawsze ma działać poprawnie.
Develop jest gałęzią równoległą do mastera, od której rozgałęziam się na gałęzie gdzie wykonuję poszczególne taski. Tutaj również dbam o to aby wszystko było poprawne i kod dobrze działał. Jest to jakby ostatni element gdzie można wyłapać błąd przed mergem do mastera.
TASK_0_001_0 (gałąź tasku) – jest to przykładowa gałąź odchodząca od developa, na której realizowany jest konkretny task. Po skończeniu pracy i upewnieniu się, że wszystko działa poprawnie, jest ona mergowana do developa, a następnie kasowana.
Nazewnictwo gałęzi
Gałęzie z taskami nazywam nazwą taska, która ma następujący format TASK_X_YYY_Z. Na potrzeby tego konkretnego projektu przyjąłem następującą konwencję:
- X – przyjmuje wartości: 0 – general, 1 – Android app issue, 2 – iOS app issue,
- YYY – to numer danego issue (user story),
- Z – to numer taska dla danego issue (user story).
Merge requesty
Merge requesty dla gałęzi tasków wykonywane są do developa w momencie zakończenia pracy nad danym taskiem. Dodatkowo są one akceptowane tylko po wykonaniu review kodu (na przykład na następny dzień) w celu uniknięcia błędów.
Merge request z developa do mastera wykonywany jest co dwa tygodnie, na zakończenie sprintu. Oczywiście aby do niego doszło wszystkie testy muszą świecić się na zielono, a ja ponownie upewniam się czy na pewno nie ma żadnych błędów w kodzie.
Organizacja pracy
Jak już wspomniałem wcześniej, pracuję w nieco zmodyfikowanej wersji scruma tak więc do backlogu dodaję historyjki użytkownika (ang. user story), które nazywam według następującej konwencji: US_X_YYY: Title:
- X – przyjmuje następujące wartości: 0 – general, 1 – Android app issue, 2 – iOS app issue,
- YYY – numer issue.
Na podstawie US generuję później taski, które nazywam według następującego formatu: TASK_X_XXX_Y: Title:
- X_XXX – to po prostu nazwa US (cztery pierwsze liczby po US_),
- Y – to numer tasku dla danego US.
Oprócz tego każdy task oraz US ma przypisaną odpowiednią labelkę określającą jego priorytet. Dodatkowo też stosuję następujące labelki:
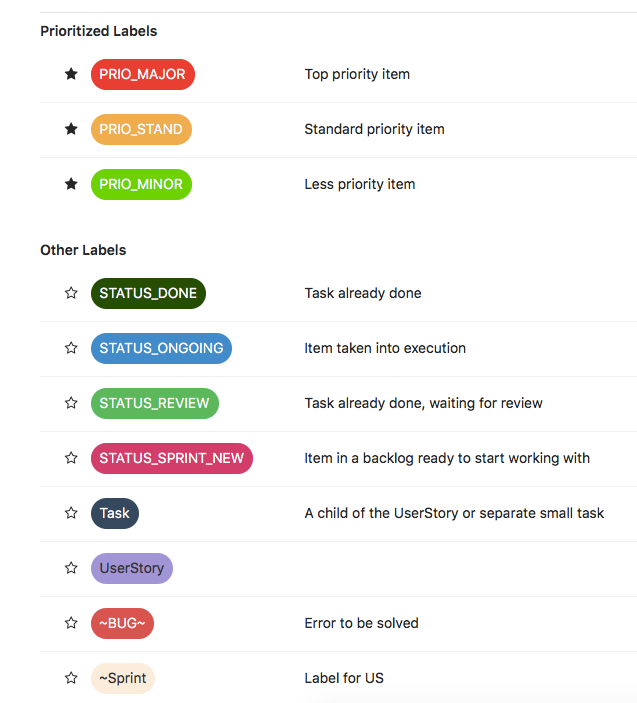
Moja tablica składa się więc z kolumn takich jak:
| Backlog | ~Sprint | STATUS_SPRINT_NEW | STATUS_ONGOING | STATUS_REVIEW | STATUS_DONE | Closed |
| … | … | … | … | … | … | … |
Taski w zależności od tego w której są kolumnie mają przypisywaną odpowiednią labelkę oraz już przy samym tworzeniu labelkę informującą o priorytecie. Dodatkowo taski tworzone w trakcie sprintu w przypadku znalezienia błędu, mają przypisywaną labelkę „~BUG~”.
Dodam jeszcze, że wszystkie taski ze STATUS_DONE przenoszone są do Closed na końcu sprintu czyli co dwa tygodnie. Wtedy też zamykam odpowiadające im US.
Sprinty
Jak już wspomniałem kilkukrotnie sprinty trwają dwa tygodnie. Na końcu sprintu zamykam wykonane taski oraz US i robie merge do mastera. Sprinty w Gitlabie oznaczam jako kroki milowe, co pozwala mi również monitorować to jaki procent zaplanowanych zadań został wykonany:
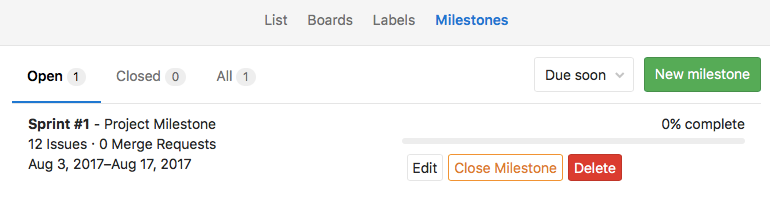
Ilustracja przedstawia „sprint #1” trwający od 3.08.17 do 17.08.17.
Podsumowanie
Jak widzicie powyżej streściłem przyjętą przeze mnie organizację pracy w projekcie „BeczkoMiafia” polegającym na stworzeniu multi-platformowej aplikacji mobilnej. O jego postępach możecie poczytać obserwując na bieżąco hasztag: #ProjektStrefaKodera. Jeśli natomiast macie jakieś pytania, recenzje, uwagi to śmiało piszcie w komentarzach ;)

Chciałem Cię zhejtować ale tak mało napisałeś że nie mam za co ;D Hy hy hy. Zapowiada się ciekawie, czekam na więcej.
Konstruktywne uwagi/sugestie mile widziane – pewnie nawet je wdrożę ;) hejt od razu kasuję tak, że szkoda tracić czas na pisanie ;)
Spoko, postaram się „nie zalać Cie falą krytyki” (parafraza z „Development blog #0: Way of Working”). :) Przyjemnie się to czyta ale ma się niedosyt informacji.
Będzie więcej artykułów, z biegiem czasu. Na przykład w czwartek podsumowanie pierwszego sprintu ;)
Przepraszam, ja tylko z litrówką: bierząco ma być przez ż ;)
Dzięki ;)
Bardzo ciekawy artykuł. Wiele firm zapomina o organizacji pracy i podczas projektów panuje prawdziwy chaos. Wcześniej pracowałem w takiej firmie, teraz przeniosłem się do krakowskiego Codete i to zupełnie inna bajka. Pracujemy w sprintach, dzielimy się wiedzą, wszystko mamy pod kontrolą, a każdy ma rozdzielone zadania – ten model zdecydowanie bardziej mi pasuje.
Hmm, to też jakiś pomysł ;) Każdy może zrobić jak mu wygodniej ;)