Elementarz Java #7 – Dziedziczenie
Wstęp
Dzisiaj mam dla Was mega dużą pigułę wiedzy związaną z tematyką „dziedziczenia”. W artykule poruszyłem wszystkie najważniejsze zagadnienia związane z tym tematem. Całość oparta jest o wiele praktycznych przykładów oraz diagramów UML. Nie przedłużając, życzę miłej lektury i owocnej nauki.
Seria #ElementarzJava składa się z następujących artykułów:
- Podstawy języka Java (kompilacja, zmienne, struktura klasy, pakiety),
- Typy danych w języku Java (deklaracja i inicjalizacja zmiennych, różnica między typami, garbage collection, typy opakowujące),
- Operatory i konstrukcje warunkowe w Java (użycie operatorów, porównywanie obiektów, instrukcje:
if,if/else,switch), - Tablice (charakterystyka tablic, tablice jedno i wielowymiarowe),
- Pętle (tworzenie pętli, instrukcje
breakicontinue, etykiety), - Metody oraz hermetyzacja (metody statyczne, przeciążanie metod, konstruktory, modyfikatory widoczności, hermetyzacja elementów klasy, parametry),
- Dziedziczenie (implementacja, przysłanianie metod, polimorfizm, rzutowanie),
- Obsługa wyjątków (kategorie wyjątków, łapanie wyjątków, klasy wyjątków),
- API Java (
String,StringBuilder, data i czas, kolekcje, wyrażenia lambda).
Jesteś tu pierwszy raz? Polecam rozpocząć lekturę od materiału: Elementarz Java #0 – wprowadzenie.
Implementacja dziedziczenia
Klasy mogą dziedziczyć właściwości i zachowania z innych klas. W Javie wykorzystuje się do tego słówko kluczowe extends. Klasy mogą również implementować wiele interfejsów, a te z kolei dziedziczyć po innych interfejsach. Jak wygląda implementacja dziedziczenia? Przenalizujmy to na podstawie krótkiego przykładu oraz pomocniczego diagramu UML.
interface canRun { }
class Animals implements canRun { }
class Mammals extends Animals { }
class Horse extends Mammals { }
class Pony extends Horse { }
public class Foal extends Horse {
public static void main(String[] args) {
Foal foal0 = null;
Foal foal1 = new Foal();
Horse foal2 = new Foal();
Mammals foal3 = new Foal();
Animals foal4 = new Foal();
canRun foal5 = new Foal();
Object foal6 = new Foal();
Horse pony1 = new Pony();
Animals horse1 = new Horse();
Object animal1 = new Animals();
Foal horse2 = new Horse(); //błąd kompilacji
Foal animal2 = new Animals(); //błąd kompilacji
Foal pony2 = new Pony(); //błąd kompilacji
}
}Diagram klas dla powyższego kodu.
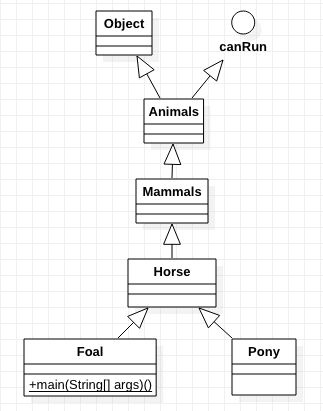
Mamy klasę Animals, która dziedziczy po Object (wszystkie obiekty w Java dziedziczą po Object) oraz implementuje interfejs canRun. Klasa Mammals, dziedziczy po Animals, klasa Horse, dziedziczy po Mammals, a klasy Foal i Pony dziedziczą po Horse. Dodatkowo klasa Foal implementuje statyczną publiczną metodę main(String[] args). W przykładzie stworzyłem kilka różnych obiektów wykorzystując mechanizm dziedziczenia. Na przykład na rzecz obiektu Mammals stworzyłem obiekt Foal. Mogłem tak zrobić dlatego, że Foal dziedziczy po Horse, a ta klasa z kolei dziedziczy po Mammals. Zasada tutaj jest bardzo prosta. Dany obiekt możemy przypisać do obiektu o typie klasy, do której możemy „dojść” za pomocą strzałek na przedstawionym wyżej wykresie. Pisząc innymi słowami, obiekt X może zostać przypisany na rzecz obiektu Y jeśli obiekt Y jest nadklasą (rodzicem) obiektu X. Nie jest więc możliwe, jak to zresztą zostało to pokazane, przypisanie obiektu Horse, Animals czy Pony na rzecz obiektu Foal.
Przysłanianie metod
Pobawiliśmy się trochę dziedziczeniem więc pora na nieco ciekawszy przykład. Czy taki kod zostanie skompilowany poprawnie?
class School {
protected Integer number() {
//…
}
}
public class Class extends School {
public Number number() {
//…
}
}Odpowiedź na to pytanie pytanie brzmi – nie. Problem jaki tutaj wynika dotyczy tak zwanych typów kowariantnych (ang. covariant type). W poprzednim przykładzie tłumaczyłem, że dany obiekt możemy przypisać na rzecz innego obiektu, jeśli jest on jego rodzicem. Identyczna zasada dotyczy typów zwracanym przysłanianych metod. Popatrzmy na schemat.
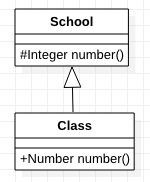
Mamy tutaj klasę Class, która dziedziczy po School. W obu klasach mamy metodę number. Jest jednak pewien błąd. Jeśli klasa Class dziedziczy po School to tak samo typ zwracany metody number z klasy Class powinien dziedziczyć po typie zwracanym metody number z klasy School. W naszym kodzie jest dokładnie na odwrót.
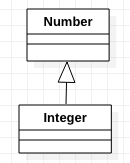
Aby „naprawić” nasz przykład musimy więc zamienić Number z Integer.
class School {
protected Number number() {
//…
}
}
public class Class extends School {
public Integer number() {
//…
}
}Teraz wszystko będzie w porządku. Jak już poruszyłem temat przysłaniania metod no to lecimy dalej. Jaki będzie efekt działania takiego kodu?
interface Test {
public default Number getNumber() {
return 0;
}
}
public class Main implements Test {
public Integer getNumber() {
return 1;
}
public static void main(String[] args) {
System.out.print(new Main().getNumber());
}
}Powyższy przykład to „klasyczne” przysłonięcie metody getNumber przez metodę o tej samej nazwie, ale zaimplementowaną w klasie Main. Tutaj trzeba zwrócić uwagę na jedną rzecz. Klasa Main implementuje interfejs Test. Jak dobrze wiemy implementacja interfejsu wiąże się również z implementacją metod jakie ten interfejs udostępnia. W tym przypadku jest jednak nieco inaczej. Metoda getNumber nie musi być implementowana w klasie Main i gdyby tak było to przy tworzeniu obiektu klasy Main została by wywołana implementacja zdefiniowana w interfejsie. Na ekranie pojawiła by się cyfra 0. My jednak zdecydowaliśmy się na przysłonięcie metody getNumber czyli zaimplementowanie nieco innego „zachowania” w klasie Main. Efektem uruchomienia powyższego przykładu będzie więc wypisanie 1. Przejdźmy do kolejnego zadania.
class Book {
public void name(double number) {
System.out.print("Book ");
}
}
public class Magazine extends Book {
public void name(int number) {
System.out.print("Magazine ");
}
public static void main(String[] args) {
Magazine magazine = new Magazine();
magazine.name(1);
magazine.name(1.0);
}
}Co tu się dzieje? Mamy obiekt typu Magazine i wywołujemy dwukrotnie metodę name, raz z liczbą 1 czyli intem, a drugi raz z liczbą 1.0 czyli doublem. Problem jaki może się tutaj pojawić związany jest z wywołaniem metody name dla double. Zwróć jednak uwagę na jedną istotną rzecz. Metoda name znajdująca się w klasie Magazine nie przysłania metody name z klasy Book. Mamy tutaj zaimplementowany mechanizm, który nazywa się przeładowaniem metod. Posługując się obiektem typu Magazine, możemy wywoływać dowolną wersję metody name w zależności od tego jaki typ danych przekażemy w argumencie. Nasz kod wypisze więc „Magazine Book”.
W materiale na temat zmiennych pisałem o słówku kluczowym final. Jak już wspomniałem, ma ono zastosowanie również przy okazji metod. Przenalizujmy taki program.
class Book {
public final void name() {
System.out.println("Book");
}
}
public class Magazine extends Book {
public void name() {
System.out.println("Magazine");
}
}Jeśli przy deklaracji zmiennej zastosujemy słówko kluczowe final, wtedy taka zmienna staje się stałą. To samo dzieje się przy metodach. Powyższy kod nie zostanie skompilowany dlatego, że metoda name oznaczona słówkiem kluczowym final nie może być przysłaniana, ale może być przeciążana. W naszym przykładzie jest przysłaniana co powoduje błąd kompilacji.
Wyczerpując tematykę implementacji dziedziczenia zastanówmy się jeszcze nad dziedziczeniem klas abstrakcyjnych.
abstract class Animal {
public abstract void canRun();
}
public class Cheetah extends Animal {
public void canRun(Boolean value) {
System.out.println("Go...");
}
}Powyższy kod nie zostanie skompilowany. Dziedzicząc po klasie abstrakcyjnej należy przysłonić wszystkie metody abstrakcyjne jakie ta klasa implementuje. Pamiętaj również, że przy okazji metod abstrakcyjnych nie definiuje się ich ciał. W naszym przykładzie metoda canRun w klasie Cheetah nie przysłania metody canRun z klasy Animal lecz ją przeładowuje. Powoduje to finalnie błąd kompilacji.
Do tej pory wszystkie metody, które były przysłaniane miały modyfikator dostępu publiczny lub chroniony. To trochę upraszczało sprawę, no bo jak wiadomo metody publiczne widoczne są „wszędzie”, a chronione w tym samym pakiecie oraz klasach dziedziczących. Pytanie jakie może się pojawić to co z metodami prywatnymi, które przecież w klasie dziedziczącej nie będą dostępne?
public abstract class Document {
private void type() {
System.out.print("Type is undefined");
}
public static void main(String[] args) {
Document document = new Passport();
document.type();
}
}
class Passport extends Document {
protected void type() {
System.out.print("Passport");
}
}Rezultatem wywołania powyższego kodu będzie wyświetlenie napisu „Type is undefined„. Dzieje się tak dlatego, że metoda type z klasy Document oznaczona jest jako prywatna. Co za tym idzie nie jest widoczna dla klasy Passport. Jeśli na rzecz obiektu o typie Document tworzymy obiekt typu Passport to w „normalnej” sytuacji metoda type z klasy Document powinna zostać przysłonięta przez metodę type klasy Passport. W tym przypadku tak się jednak nie dzieje. Metoda type z klasy Document nie jest widoczna dla klasy Passport. Nie może więc ona zostać nadpisana ani przysłonięta. Finalnie wywoływana jest metoda type z klasy Document gdyż nie jest ona przysłonięta.
Rola i użycie polimorfizmu
W poprzednich przykładach metody z nadklasy oraz podklas miały te same nazwy. Nie był to przypadek, ale zamierzone działanie, które ma zresztą swoją nazwę. Mowa oczywiście o polimorfizmie. „Polimorfizm” w dosłownym tłumaczeniu to „wiele form”. W Javie o polimorfizmie mówimy wtedy, kiedy między klasami zachodzi relacja dziedziczenia, a zarówno klasa nadrzędna jak i podklasa mają zdefiniowane metody o tej samej nazwie. Metody polimorficzne nazywane są również metodami przysłoniętymi (ang. overridden method). Metody przysłonięte powinny mieć tę samą nazwę i tą samą listę argumentów. Typ zwracany powinien być taki sam lub powinna to być podklasa typu zwracanego w metodzie bazowej (to właśnie ten przykład z typami kowariantnymi, który opisałem nieco wyżej). Modyfikator widoczności musi być również identyczny lub mniej restrykcyjny. Pamiętaj jednak, że w przypadku przeładowania tych samych metod, nie ma mowy o polimorfizmie. Na zakończenie tego tematu przenalizujmy jeszcze taki kod.
class Country { }
class State extends Country { }
public class City extends State {
public String getName() {
return "Kraków";
}
public static void main(String[] args) {
State state = new City();
System.out.print(state.getName());
}
}Jak pewnie się domyślasz, ten kod nie zostanie skompilowany poprawnie. W metodzie main, mamy tworzony obiekt typu City na rzecz obiektu typu State. Następnie wywołujemy metodę getName. Wywołanie tej metody jest polimorficzne (ewidentnie widać, że autor miał tutaj na myśli zastosowanie mechanizmu przysłaniania metod). Problem polega jednak na tym, że w obiekcie State ani Country nie zdefiniowaliśmy publicznej lub też chronionej metody getName (w przypadku modyfikatora private, dalej nie było by możliwe przysłonięcie, a dodatkowo wywołanie getName z poziomu klasy City nie wchodziło by w grę, bo modyfikator private umożliwia korzystanie z takiej metody tylko w klasie w której została ona zdefiniowana). Mechanizm przysłaniania nie będzie miał jak zadziałać. Dostaniemy więc błąd kompilacji.
Na marginesie dodam jeszcze, że metoda getName mogła by zostać zdefiniowana w klasie Country, gdyż jest ona rozszerzana przez klasę State. Oznacza to, że klasa State dziedziczy wszystkie własności oraz zachowania z klasy Country. Dziedziczyła by również metodę getName, która była by poprawnie przysłaniana przez tą samą metodę z klasy City.
Różnica między typem referencji i obiektu
Dostęp do obiektów w Java odbywa się przez referencję. Odwołując się do klasy pochodnej możemy zrobić to przy pomocy zmiennej (referencji) o typie klasy bazowej lub interfejsu. Nie jest możliwe odwoływanie się do klasy bazowej przy użyciu zmiennej o typie klasy pochodnej. Jeśli do obiektu odwołujemy się poprzez zmienną referencyjną klasy bazowej to możemy uzyskać dostęp tylko do zmiennych i metod zdefiniowanych w klasie bazowej. Dostęp do metod z klasy pochodnej jest możliwy przez polimorfizm. Jeśli do obiektu odwołujemy się przez zmienną o typie zaimplementowanego przez klasę bazową interfejsu, możemy uzyskać dostęp tylko do zmiennych i metod zdefiniowanych przez ten interfejs. Typ obiektu określa jakie jego właściwości zapisywane są w pamięci. Do wszystkich obiektów w pamięci możemy „dostać się” za pomocą zmiennej typu java.lang.Object. Na zakończenie warto jeszcze dodać, że wszystkie zmienne tablicowe zdefiniowane przez programistę mają typ referencji (nie obiektowy).
int[] ints; long[] longs; String[] strings; Object[] objects;
To są wszystko typy referencyjne (nie prymitywy).
Rzutowanie
Java w pewnych przypadkach umożliwia niejawne rzutowanie typów danych. Zasada jest tutaj prosta. Jeśli przykładowo mamy liczbę typu int to możemy ją bez jawnego rzutowania przypisać do zmiennych o typie, który nie powoduje utraty precyzji, dla int będzie to: long, float, double czy też Object. Strukturę dziedziczenia typów danych przedstawiłem na poniższej grafice.
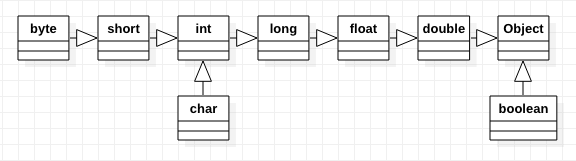
Popatrzmy na parę praktycznych przykładów.
byte x = 5, y = 10; ... result = x + y;
Mamy tutaj dwie liczby typu byte, które dodajemy do siebie i przypisujemy do nowej zmiennej. Chodź są to typy byte to po dodaniu będą traktowane jak int. Zmienna result może więc być typu int, long, float, double, Object lub po jawnym rzutowaniu byte albo short.
long x = 2; ... resutl = 2 * x;
W tym wypadku mnożymy wartość zmiennej typu long przez 2. Wynik takiego działania będzie longiem (bo mnożyliśmy longa). Zmienna result może więc być typu: long, float, double, Object lub po jawnym rzutowaniu byte, short, int. Teraz czas na coś ciekawszego.
public class ExampleCast {
public void test(byte val) {
System.out.println("byte");
}
public void test(int val) {
System.out.println("int");
}
public void test(float val) {
System.out.println("float");
}
public void test(Object val) {
System.out.println("Object");
}
public static void main(String[] args) {
ExampleCast exampleCast = new ExampleCast();
byte b = 1;
short s = 1234;
int i = 12345;
long l = 123456;
float f = 1.23f;
double d = 1.234;
exampleCast.test(b);
exampleCast.test(s);
exampleCast.test(i);
exampleCast.test(l);
exampleCast.test(f);
exampleCast.test(d);
exampleCast.test(true);
}
}Mamy tutaj przeładowaną metodę test, która przyjmuje różne typy argumentów. Cała zabawa polega na tym, że metoda ta jest również wywoływana z danymi o typie dla których nie została zdefiniowana. Jak więc zadziała program? Po jego uruchomieniu otrzymamy następujące wyjście:
byte int int float float Object Object
Dla zmiennej typu byte, została uruchomiona metoda przyjmująca argument typu byte. Dla zmiennej typu short została uruchomiona metoda przyjmująca argument typu int. W tym przypadku Java automatycznie zrzutowała dane do najbliższego możliwego typu i uruchomiła stosowną metodę. Dalej postępujemy analogicznie (zgodnie ze schematem opublikowanym wyżej). Dla utrwalenia jeszcze jeden przykład związany z prymitywami.
public class ExampleCast {
ExampleCast(int val) {
System.out.println("int");
}
ExampleCast(Object val) {
System.out.println("Object");
}
public static void main(String[] args) {
new ExampleCast(1);
new ExampleCast(100L); //long
}
}Efektem działania takiego programu będzie wypisanie wartości “int” (dla metody uruchamianej z intem) oraz „Object” (dla metody uruchamianej z longiem). Jeśli jesteśmy w tematyce rzutowania to nie można również zapomnieć, że ten sam mechanizm dotyczy obiektów, które sami stworzyliśmy. Popatrzmy na taki kod.
class Parent { }
class Child extends Parent { }
public class Main {
public static void main(String[] args) {
Object object = new Parent();
Child child = (Child) object;
}
}Czy zostanie on skompilowany poprawnie? To pytanie jest trochę podchwytliwe bowiem – tak. Przenalizujmy co się tutaj dzieje. Na początku na rzecz obiektu typu Object przypisujemy obiekt typu Parent. Nie ma w tym najmniejszego problemu bowiem wszystkie obiekty w Javie dziedziczą po Object. Pewien kłopot jest w linijce niżej. Tutaj znowu utworzony chwilę wcześniej Object jest rzutowany do obiektu typu Child. Czy jest to możliwe? Popatrzmy na schemat.

Najpierw klasę Parent rzutujemy na Object, a następnie na tym samym obiekcie chcemy wykonać rzutowanie do Child. To nie jest jednak możliwe. Szkopuł polega na tym, że kompilator w momencie kompilacji o tym nie wie. Kod ten zostanie więc skompilowany i uruchomiony. Dopiero w trakcie działania programu zostanie rzucony wyjątek ClassCastException. Na marginesie dodam, że gdyby zmienna object została by zrzutowana do obiektu typu Parent to wszystko by zadziałało.
Użycie super oraz this
Słówka kluczowe super oraz this są referencją do obiektu. Inicjalizowane są one przez maszynę wirtualną Javy dla każdego obiektu znajdującego się w pamięci. Słówko kluczowe this zawsze wskazuje na własną instancję obiektu, natomiast super odnosi się do pól oraz metod klasy bazowej. Popatrzmy na krótki przykład.
public class Test {
String name;
Test(String name) {
this.name = name;
}
public static void main(String args) {
System.out.print(new Test().name);
}
}Powyższy fragment wykorzystuje słówko kluczowe this, do inicjalizacji pola name klasy Test.
class Parent {
String name;
}
class Child extends Parent {
public void method(String name) {
super.name = name;
}
}W tym przykładzie wykorzystaliśmy słówko kluczowe super to inicjalizacji pola name z klasy bazowej.
Instrukcje this oraz super mogą zostać wykorzystywane również do uruchomienia innych konstruktorów. Na początku muszę tutaj napisać o jednej istotnej zasadzie: this oraz super musi być pierwszą instrukcją w konstruktorze i nie może być wywoływane z poziomu innych metod. W przypadku this, uruchamiamy innych konstruktor obiektu, na który wskazujemy, a w przypadku super uruchamiany jest konstruktor klasy nadrzędnej.
public class Test {
public Test() {
this("Hello ");
System.out.print("world!");
}
public Test(String arg) {
System.out.print(arg);
}
public static void main(String[] args) {
new Test();
}
}Instrukcja this(“Hello”) umieszczona w konstruktorze bezargumentowym uruchomiła drugi konstruktor, znajdujący się w tej samej klasie ale przyjmujący jako argument ciąg znaków. Efektem działania powyższego programu będzie wyświetlenie napisu „Hello world!”.
class Furniture {
public Furniture(String name) {
System.out.println(name);
}
}
public class Chair extends Furniture {
public Chair() {
System.out.println("Chair");
}
public static void main() {
new Furniture("Furniture");
}
}Tutaj mała niespodzianka. Kod, który zamieściłem wyżej nie zostanie skompilowany. W konstruktorze bezargumentowym klasy Chair mamy niejawnie wywołaną instrukcję super(), a klasa Furiniture nie ma zaimplementowanego konstruktora bezargumentowego. Java tworząc instancję obiektu podklasy wywołuje niejawnie z poziomu dowolnego konstruktora podklasy, instrukcję super(). Wyjątkiem od tej reguły jest zdefiniowanie własnego wywołania instrukcji super. Przypominam również, że jeżeli w klasie bazowej nie zostanie zdefiniowany żaden konstruktor, to przy wywoływaniu jawnym bądź nie, instrukcji super() nie będziemy mieli błędu. Zostanie wtedy uruchomiony konstruktor domyślny.
class Furniture {
public Furniture() {
System.out.println("Hello!");
}
}
public class Chair extends Furniture {
public Chair(String name) {
System.out.println(name);
}
}W tym przykładzie, mamy konstruktor w podklasie, który jak argument przyjmuje zmienną typu String. Tutaj również niejawnie będzie wywołana instrukcja super(). Zostanie więc wywołany bezargumentowy konstruktor z nadklasy.
class Furniture {
}
public class Chair extends Furniture {
public Chair(String name) {
System.out.println(name);
}
}Jak już wspominałem, brak zdefiniowanego konstruktora bezargumentowego w nadklasie nie powoduje błędu przy niejawnym wywołaniu super(). Zadziała konstruktor domyślny.
class Furniture {
public Furniture(String val) { }
}
public class Chair extends Furiniture {
public Chir() {
this(1);
}
public Chair(int val) {
this("1");
}
public Chair(String val) {
super(val);
}
}Ten przykład zostanie uruchomiony poprawnie. Przenalizujmy krok po kroku co tu się dzieje. W konstruktorze Chair() mamy instrukcję this(1). Z racji tego, że super() musi być pierwszy (tak samo jak this()) nie ma tutaj wywołania niejawnego super() – gdyby było, otrzymalibyśmy błąd kompilacji (tak stało by się po usunięciu this(1)). Niejawne wywołanie super() mogło by pojawić się dopiero w konstruktorze Chair(String val) ale tak nie jest, ponieważ jawnie wywołaliśmy super(""). Nie powoduje to błędu kompilacji, bo taki konstruktor w klasie nadrzędnej występuje. Dodam jeszcze, że w konstruktorze Chair(String val) nie mogliśmy wstawić przykładowo this() – nie możemy zapętlać wywołań konstruktorów.
Klasy abstrakcyjne oraz interfejsy
Interfejsy
Interfejsy mogą używać słowa kluczowego extends do dziedziczenia po innych interfejsach. Może to być wiele interfejsów jednocześnie. Przykładowo dopuszczalna jest taka konstrukcja.
interface interface1 { }
interface interface2 { }
interface interface3 extends interface1, interface2 { }Oczywiście klasa, która implementuje interfejs rozszerzający inny interfejs musi implementować metody ze wszystkich tych interfejsów.
interface Test {
public void printName();
}
interface Test2 extends Test {
public void printScore();
}
public class ExampleTest implements Test2 {
public void printName() { }
public void printSocre() { }
}Jak widać musieliśmy zaimplementować metody z obydwu interfejsów. Co ciekawe klasa może implementować wiele interfejsów, które mają te same nazwy pól lub metod. Dochodzi wtedy do ich przysłaniania przez interfejs znajdujący się „niżej w hierarchii”.
interface Interface1 {
int count = 0;
default void method1() {
System.out.println("method1");
}
}
interface MyInterface extends Interface1 {
int count = 1;
default void method1() {
System.out.println("method2");
}
}
public class Test implements MyInterface {
public static void main(String[] args) {
System.out.println(count);
new Test().method1();
}
}Powyższy przykład wypisze: 1 oraz method2. Jeśli interfejsy nie dziedziczyły by po sobie to wtedy wymagana była by implementacja takiej metody bądź metod (nawet jeśli była by to klasa abstrakcyjna lub metody były by statyczne albo domyślne – zawierały ciało).
Wszystkie pola w interfejsie domyślne są typu public static final. Metody w interfejsie domyślnie są typu public abstract chyba, że zostały zdefiniowane jako statyczne lub domyślne (wtedy nie są abstrakcyjne). Jeśli w konkretnej klasie przy metodzie zdefiniowanej w interfejsie, a którą chcemy zaimplementować, nie mamy modyfikatora dostępu, metoda ta jest typu „package-private” czyli nie jest implementacją metody z interfejsu (nie zgadzają się modyfikatory dostępu).
interface Computer {
String getName();
}
public class PersonalComputer implements Computer {
String getName() {
return "MyComputer";
}
}Ten kod nie zostanie skompilowany. W klasie PersonalComputer nie implementujemy metody getName, zdefiniowanej w interfejsie. Nie zgadza się modyfikator dostępu.
Klasa abstrakcyjna może, ale nie musi implementować metod z interfejsu.
interface Computer {
public abstract String getName(); //słówka kluczowe public i abstract są tutaj nadmiarowe
}
abstract class NoteBook implements Computer {
abstract String getModelNumber();
}
public class MacBook extends NoteBook {
public String getName() {
return "MacBook Pro";
}
String getModelNumber() {
return "ABC123456789";
}
}Ten kod będzie skompilowany poprawnie. Pierwszą konkretną podklasą (ang. concrete subclass) jest klasa MacBook. Klasa abstrakcyjna implementująca interfejs nie musi implementować jego metod. Musi to zrobić pierwsza konkretna podklasa, czyli klasa dziedzicząca nie będąca abstrakcyjną. Jest jedna uwaga. Jeśli już decydujemy się na implementację metod zdefiniowanych w interfejsie, to musimy pamiętać o modyfikatorach dostępu. Nie jest dopuszczone takie rozwiązanie.
interface Test {
int method();
}
public class Main implements Test {
int method() {
return 0;
}
}Nie zgadza się tutaj modyfikator dostępu. Jest to nieoprawne nadpisanie metody z interfejsu. Dostaniemy błąd kompilacji.
interface Test {
public static void play();
public String stop() {
return "Stop";
}
}Powyższy kod jest błędny. Metody statyczne (oraz domyślne) w interfejsie muszą mieć ciało. Domyślnie metody w interfejsie nie mają ciała (są abstrakcyjne). Jeśli chcemy, aby miały ciało muszą być oznaczone jako static lub default.
interface MyInterface {
static void method1() {
System.out.println("static method");
}
default void method2() {
System.out.println("default method");
}
}Pewnie zastanawiasz się teraz czym się różni metoda statyczna zdefiniowana w interfejsie od metody domyślnej zdefiniowanej w interfejsie. Różnica polega na sposobie ich wywołania. Metoda statyczna interfejsu nie może być wywoływana przy użyciu zmiennej referencyjnej. Możemy ją uruchomić poprzez bezpośrednie użycie interfejsu. Metoda domyślna, chociaż nie jest implementowana w klasie (jej implementacja nie jest zabroniona) może być wywołana tak jak by w tej klasie była zdefiniowana.
interface MyInterface {
static void method1() {
System.out.println("static method");
}
default void method2() {
System.out.println("default method");
}
}
public class Test implements MyInterface {
public static void main(String[] args) {
MyInterface.method1();
MyInterface.method2(); // niepoprawne wywołanie metody domyślnej interfejsu
new Test().method1(); // niepoprawne wywołanie metody statycznej interfjesu
new Test().method2();
}
}Po usunięciu dwóch błędnych linijek, kod ten zostanie skompilowany poprawnie. Obie metody mogą zostać również przysłonięte (o czym pisałem wyżej).
interface MyInterface {
static void method1() {
System.out.println("static method");
}
default void method2() {
System.out.println("default method");
}
}
public class Test implements MyInterface {
public static void method1() {
System.out.println("static class method");
}
public void method2() {
System.out.println("default class method");
}
public static void main(String[] args) {
MyInterface.method1(); // tutaj zostanie wywołana metoda z interfejsu
Test.method1(); // method1 jest przysłaniana przez metodę z klasy Test
new Test().method2(); // method2 jest przysłaniana przez metodę z klasy Test
}
}Interfejsy nie definiują żadnych konstruktorów.
Klasa abstrakcyjna
Dziedzicząc po klasie abstrakcyjnej należy zaimplementować jej abstrakcyjne metody (dotyczy to również metod abstrakcyjnych z klas, po których dana klasa abstrakcyjna dziedziczy). Musisz tutaj pamiętać o modyfikatorach dostępu, które w konkretnej klasie (nie będącej abstrakcyjną) nie mogą być bardziej restrykcyjne od modyfikatora tej samej metody z klasy bazowej.
abstract class Furniture {
protected abstract void type(String name);
}
public class Table extends Furniture {
protected void type(String name) {
}
}Metoda type w powyższym przykładzie, może mieć modyfikator dostępu protected lub public. Nie możemy mieć modyfikatora dostępu bardziej restrykcyjnego niż protected (np. package-private albo private). Reguła ta nie dotyczy oczywiście metod przeładowanych. Klasa Table może więc zawierać metodę private void type() { }, jeśli dodatkowo zostanie zaimplementowana metoda abstrakcyjna (przyjmująca argument typu String).
public abstract class Test {
public abstract void method() {}
}
public class Test2 {
public abstract void method();
}Ten kod nie zadziała. Mamy tutaj dwa błędy, metoda abstrakcyjna nie może mieć ciała oraz metod abstrakcyjnych nie możemy umieszczać w klasie, która nie jest abstrakcyjna. W klasach abstrakcyjnych możemy za to umieszczać również metody, które nie są abstrakcyjne. Mogą one być normalnie dziedziczone przez inne klasy.
Nie możemy stworzyć instancji klasy abstrakcyjnej.
Klasa abstrakcyjna vs interfejs
Najczęstsze pytanie jakie pada podczas rozmów rekrutacyjnych: Czym różni się klasa abstrakcyjna od interfejsu? W Java zasady są następujące:
- Obie konstrukcje mogą zawierać pola typu
public static final, - Mogą być rozszerzane przez słowo kluczowe
EXTENDS, - Wymagają konkretnej podklasy do utworzenia instancji (interfejs musi być implementowany, a klasa abstrakcyjna musi być dziedziczona),
- W interfejsie możemy zdefiniować metody „domyślne”, w klasie abstrakcyjnej nie,
- W interfejsie domyślnie metody są publiczne i abstrakcyjne (w tym mogą mieć tylko modyfikator
public), - W interfejsie pola są publiczne, statyczne i finalne. W klasie abstrakcyjnej mamy pod tym względem dowolność,
- Klasa abstrakcyjna może dziedziczyć po jednej klasie, a implementować wiele interfejsów.

Myślałam, że polimorfizm mam już przerobiony dogłębnie, a dopiero po tym artykule wyszło, jak mało rozumiałam ;) wielkie dzięki za tak szczegółowe tłumaczenie i konkretne informacje! Przydałyby się jeszcze artykuły z bardziej zaawansowanych tematów, bo masz dar tłumaczenia zawiłych kwestii :)